One of the major challenges while working with financial transactions and the related transaction data is understanding the relationships between various attributes present in the dataset. For example, how does the age of an account holder correlate with fraud? Is it a necessary attribute? Does it create any form of bias? A data scientist answers these questions based on domain knowledge expertise, selecting relevant features from the dataset and removing irrelevant information before training the model. With the current infrastructure, pre-trained Large language models (LLMs), like OpenAI, Gemini, Claude, etc., that are accessible via APIs and are used for extracting the relevant information from the data, helping data scientists in the tedious task of analyzing the data of financial transactions.
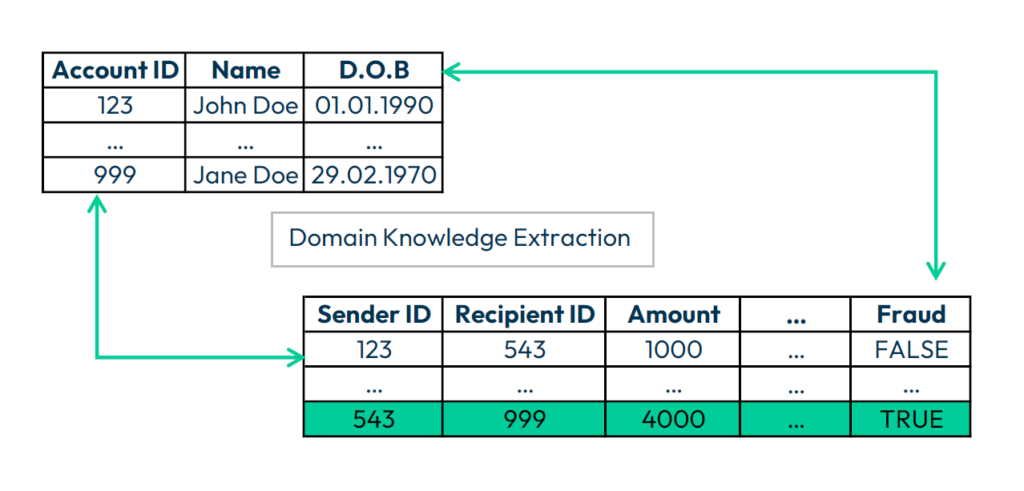
Understanding Data
Transaction data records exchanges between entities, typically involving persons or bank accounts. This data is structured in tables and includes both numerical and categorical attributes. For example, a bank transaction might include the transaction amount (numerical), the type of transaction (categorical), and the date and time (temporal). Thus transaction data differs from many other common sources of data used in training of machine learning (ML) and deep learning (DL) models.
The Challenge of Heterogeneity
Unlike text or images, transaction data combines multiple types of information, making it difficult to apply traditional machine learning techniques effectively. While images, text, audio and video data are all considered unstructured data, they are often easier to model because of homogeneous features facilitating simpler preprocessing pipelines. For structured data like transaction data, the challenge lies in extracting relevant information for feature selection – a process that relies heavily on domain knowledge. This step is crucial for training ML models. e.g. decision trees, tree-based models, etc., which are widely used in the financial sector due to their ease of explainability and suitability.
Transformer Models for Tabular Data
Encoders in transformer models focus on capturing meaningful representations of input data by generating embeddings that retain contextual information. These embeddings are particularly useful for classification tasks, anomaly detection, and feature extraction in financial transactions. Decoders, on the other hand, leverage these embeddings to generate new data points, making them more suitable for tasks like synthetic data generation, data augmentation, and predictive text-based tasks.
With the advent of transformer architectures like BERT, GPT and advanced research in the financial sector like TaBERT and UniTTab, studies have shown that encoder architectures are particularly effective for downstream tasks such as classification and regression. These methods are valuable for fraud detection and AML analysis where models determine if a data point is likely to be a fraudulent or linked to money laundering. Meanwhile, decoder architecture facilitates the generation of synthetic data using learned embeddings from real data.
- Two notable transformer models have significantly advanced tabular data analysis: TaBERT: TaBERT encodes transaction sequences in hierarchical order. A field-level transformer first processes each transaction individually for each account to create transaction embeddings. These are then used in downstream tasks such as fraud detection.
- TabGPT: TabGPT generates realistic synthetic tabular data, adapting generative models to produce synthetic tabular time series data. This is especially useful for privacy-sensitive applications, where real data cannot be shared directly.
LLMs, particularly those leveraging encoder architectures, offer significant advantages by embedding domain knowledge into embeddings that can be used for fraud detection and anti-money laundering tasks. Their ability to handle heterogeneous data, capture temporal dynamics, and generate synthetic data for privacy protection and scale to large datasets makes them a valuable tool for financial institutions and businesses.
The Future of Large Language Models in Financial Transaction Analysis
There is no doubt that the applications in transaction data analysis of LLMs will continue to play a growing role. They are likely to provide even more sophisticated and accurate insights. However, two key questions remain:
- Can these models be trusted to make fair and decisions about individuals? At spotixx we are exploring this question in our research project transfAIr.
- Are these models cost- and time-efficient enough to be deployed into real-world production systems?
While LLMs show promise, addressing these challenges will be critical to their widespread adoption in financial crime prevention.

Author:
Ajay Chawda, Data Scientist
Ready to revolutionize your approach to fraud prevention? We’re at the forefront of integrating LLMs and collaborative data strategies. Let’s connect and explore the future of financial security together! Feel free to reach out to us!
Literature
Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 2019.
Garuti, Fabrizio, et al. “Large-Scale Transformer models for Transactional Data.” CEUR WORKSHOP PROCEEDINGS. Vol. 3762. CEUR-WS, 2024.
Padhi, Inkit, et al. “Tabular transformers for modeling multivariate time series.” ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
Yenduri, Gokul, et al. “Gpt (generative pre-trained transformer)–a comprehensive review on enabling technologies, potential applications, emerging challenges, and future directions.” IEEE Access (2024).
Yin, Pengcheng, et al. “TaBERT: Pretraining for joint understanding of textual and tabular data.” arXiv preprint arXiv:2005.08314 (2020).